WEB The evaluations showed that Mistral 7B significantly outperforms Llama 2 13B on all metrics and is on. WEB Mistral 7B shines in its adaptability and performance on various benchmarks while Llama 2 13B excels. In the world of language models the competition is. WEB In this blog post we compared the performance of three large language models LLMs - RoBERTa. WEB In the battle of Mistral 7B vs. Mistral 7B stands out in the AI landscape with its remarkable. WEB My current rule of thumb on base models is sub-70b mistral 7b is the winner from here on out until llama-3 or other new. A notable metric for comparing models in the costperformance..
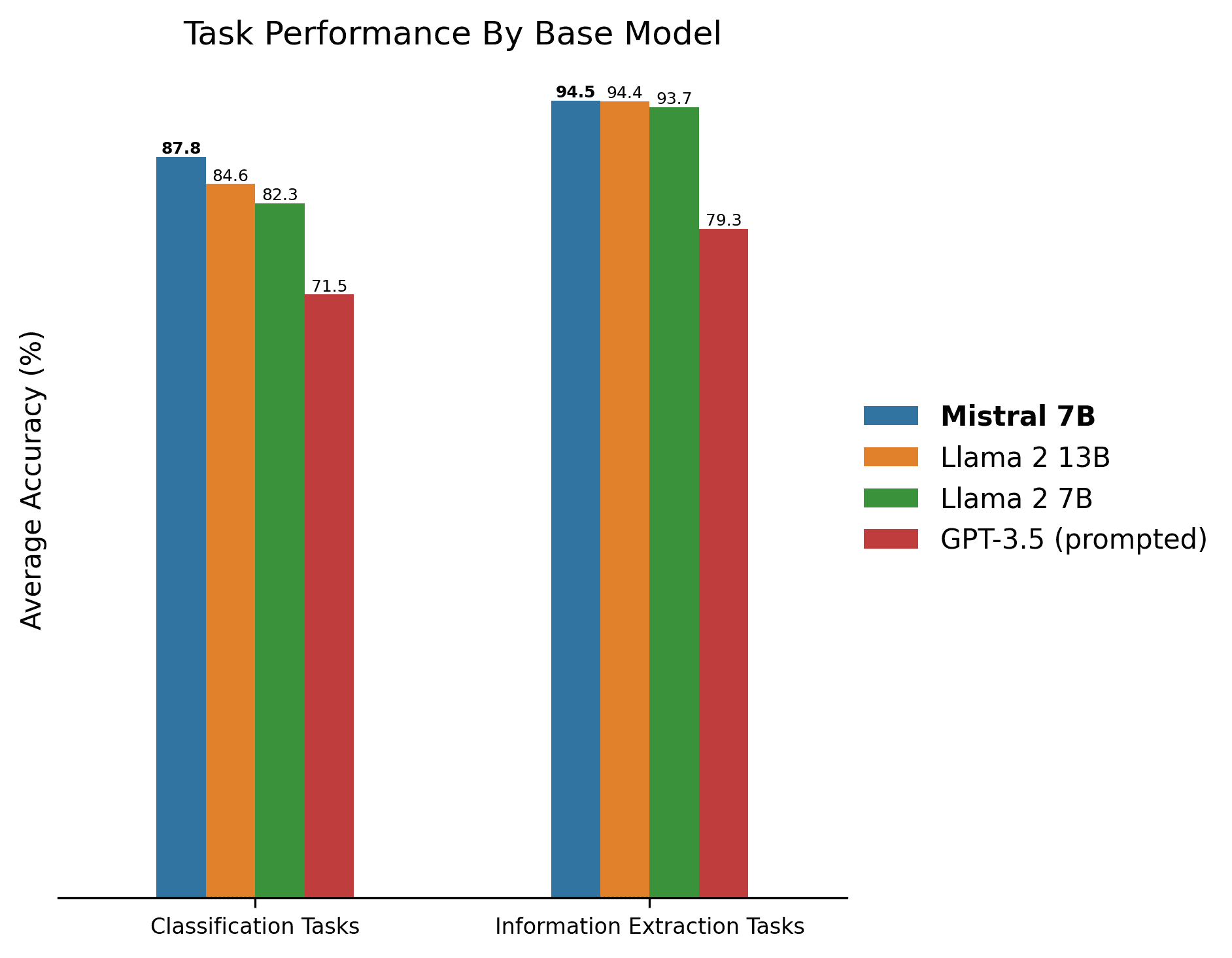
Openpipe
Result All three model sizes are available on HuggingFace for download Llama 2 models download 7B 13B 70B Ollama Run create and share large language models. Result Just grab a quantized model or a fine-tune for Llama-2 TheBloke has several of those as usual. Result OpenAI compatible local server Underpinning all these features is the robust llamacpp thats why you have to download the model in GGUF. Download the Llama 2 Model There are quite a few things to consider when deciding which iteration of Llama 2 you need. ..
Result Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your pets. Open source free for research and commercial use Were unlocking the power of these large language models Our latest version of Llama Llama. Experience the power of Llama 2 the second-generation Large Language Model by Meta Choose from three model sizes pre-trained on 2 trillion. Result Subscribe to our newsletter to keep up with the latest Llama updates releases and more Llama is the next generation of our open source large language model. Llama 2 Metas AI chatbot is unique because it is open-source This means anyone can access its source code for free..
Promptfoo
Web LLaMA-65B and 70B performs optimally when paired with a GPU that has a minimum of 40GB VRAM Suitable examples of GPUs for this model include the A100 40GB 2x3090 2x4090. Web A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. Web System could be built for about 9K from scratch with decent specs 1000w PS 2xA6000 96GB VRAM 128gb DDR4 ram AMD 5800X etc Its pricey GPU but 96GB VRAM would be. This repo contains GPTQ model files for Meta Llama 2s Llama 2 70B Multiple GPTQ parameter permutations are provided. Web With Exllama as the loader and xformers enabled on oobabooga and a 4-bit quantized model llama-70b can run on 2x3090 48GB vram at full 4096 context length and do 7-10ts with the..
Post a Comment